

[: pl]
In a series of short entries, we would like to present the technical side of preparing our corpus. For us, the information gathered here will be used to document the project, but we hope that it will be useful for beginners, and a little more experienced, to encourage discussion. We encourage all interested parties to contact.
The starting point for creating a corpus is, of course, meticulous planning. Once we have decided what texts we would like to include in it, we can process the scanned source into text that can become the basis for further processing.
Where do we get the images of the sources?
In our project, we obtain images mainly from Polish digital libraries. When the source of interest to us is missing in them, we scan them ourselves.
The easiest way to search Polish digital libraries is by using FBC search enginesbut it is also useful for Polish sources in foreign libraries Europeana. We use archive.org or Google Books less often: the files available in them are not always suitable for later processing. And no, it's not just that about famous artifacts…


What's next for the scans?
1. From PDF / DJVU to TIFF
Conversion to * .tiff image files is provided by Unix tools:
2. Image optimization
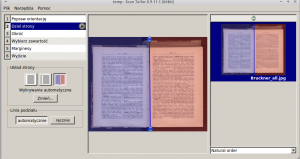
Although OCR programs often contain image optimization tools, and there are also useful scripts for this, in our work we use ScanTailora. We run the program on the command line, but it has a quite intuitive interface, so even less experienced users will have no problems using it.


3. From image to text
In previous years, we used the most popular commercial program, Abbyy FineReader, to recognize the text. In the new edition, we decided to use only free software, which, however, is of equal quality, and often exceeds paid solutions. Our choice (there will be an opportunity to write about its reasons) fell on Tesseract, powered by Google and using deep learning algorithms. Tesseract you can, of course, train yourself, but you can download from the Linux repositories and from the project's website ready-to-use data for over 130 languages and 35 types of writing.
For us, as you can guess, the most important thing is service:
- languages: Latin, Polish, German and
- letters: the so-called fractals.
Most importantly, tesseract He is good at multilingual text, and our sources do not lack this:


We save the recognized text in two formats: the well-known TXT and hOCRwhich also stores information about text blocks recognized by the OCR program, text position on the page, etc. Why is this information important to us? About that …
... in the next episode of our series
- hOCR, PAGE XML and other creatures
- what is PoCoTo and what is it for?
- how to rewrite with Transkribus
[:]


